Jupyter¶
- We'll use "Jupyter Notebook" to interact with Python.
- Like Matlab's 'Live Editor'; Maple's and Mathematica's notebooks.
- Runs in a web browser.
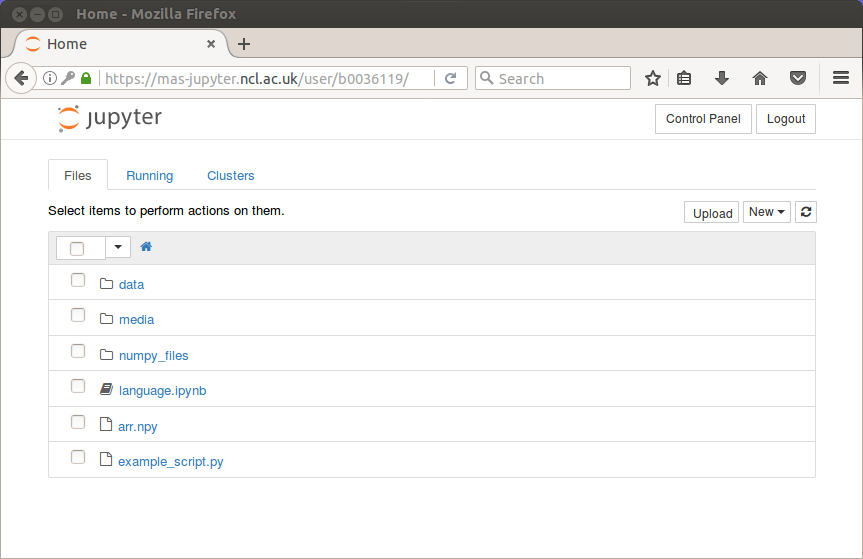
You can edit the code samples from the slides live and run them as you please.
- Double-click a cell to edit it.
- To run a cell's contents, use
Control-Enter. - You can also use
Shift-Enterto run and move to the next cell.
x = 1 + 1
10 * x
Today's course has two parts:
Morning: the Python language¶
- Why, what, how?
- Basic data types and operations
- Control flow
Afternoon: Python tools for scientists¶
NumPy: working with large data gridsSciPy: common numerical functionsmatplotlib: in-depth plotting library
Plus advice, links to resources, exercises, ...
What is Python?¶
- Interpreted, object-oriented programming language
- Works on PC, Mac and Linux
- Open source: free (speech, lunch)
Why Python?¶
- Neat and friendly syntax
print("Hello, world!")
- Newbie-friendly
- Quick to write code and quick (enough) to run
- 'Batteries included': e.g. JSON data handling
import json, random
#Data obtained from http://www.imdb.com/interfaces
with open("data/top_250_imdb.json") as data_file:
films = json.load(data_file)
random.sample(films.items(), 3)
from statistics import mean
#This mean is just from the top 250!
mean(films.values())
max(films.values())
print([name for name, score in films.items() if score == 9.2])
More pros and cons discussed at the SciPy tutorial.
What can Python do?¶
- Work with large datasets (
Pandasdataframes andNumPyarrays)
import pandas #Data from Thomas Bland
df = pandas.read_csv("data/soliton_collision.csv", index_col=0)
df.shape
df.head()
- Data processing and visualisation (
matplotlibandMayaVi)
subset = df[-7:7]
import matplotlib.pyplot as plt
plt.imshow(subset, #Like Matlab's pcolor()
aspect='auto',
extent=(0, 1000, -7, 7))
colorbar = plt.colorbar()
colorbar.ax.set_ylabel('Density $|\psi|^2$', labelpad=20, rotation=270)
plt.xlabel('time $t$')
plt.ylabel('position $z$')
plt.show()

- General purpose programming language (e.g. Python runs websites)
- Got a boring task to do? Automate it!
How do I get Python?¶
Won't always have this notebook interface!
- At home: use the Anaconda distribution or vanilla Python
- At uni: talk to your Computing officer.
Python 2 or 3?¶
- Unless you're using someone else's code, use Python 3.
- Some blogs might tell you it's not supported by big packages but that's not true any more.
Can try an IDE e.g. Spyder
1 + 2
300 - 456
Python's numbers are friendly¶
-2 ** 1000 # No problems with sign or under/overflow
type(-2 ** 1000)
1 + 1.5 # Mix int and float: result is float
type(12 + 24.0) #Can check types explicitly
Golden rule: if one part of an expression is a float, the entire expression will be a float¶
Other operations¶
23 - 7.0
2 * 4
3 / 2 # division always returns a float in Python 3
3 // 2 # double-slashes force integer division
2 ** 3.0
2 ^ 6 #Bitwise or -- not very useful for scientists
Even more operations¶
(1 + 2) * (3 + 4) #Brackets work as normal
3 - 2*4 #Order of operations (BODMAS) as normal
27 % 5 #Modulo (remainder) operation
abs(-2) #Modulus (absolute value) function
Advice for working with floats¶
- Floats accumlate rounding errors
- Testing equality is tricky (should use
math.isclose)
x = 0.1 + 0.2
y = 0.15 + 0.15
print("%.20f\n%.20f" % (x, y))
from math import isclose
isclose(x, y)
complex type¶
- Python uses
jfor the imaginary unit $i$. - Has to have a number before it, to distinguish from a variable called
j.
1j * 1j
z = 2 - 4j
z + z.conjugate() # Twice the real part
- use
cmathfunctions when working with complex numbers.
import cmath
cmath.sin(0.1 + 2j)
abs(cmath.exp(2j))
Exercises¶
What are the types and values of the following expressions? Try to work it out by hand; then check in the notebook.
23 + 2 * 17 - 923 + 2 * (17 - 9.0)5 * 6 / 75 * 6 // 75 * 6.0 // 7
2.0 ** (3 + 7 % 3) // 22 ** (3 + 7 % 3) / 24 ** 0.5-4 ** 0.5(1 + 1/1000) ** 1000
- int:
48 - float:
39.0 - float:
30/7 == 4.28571...6 - int:
30 // 7 == 4 - float:
30.0 // 7 == 4.0
- float:
8.0 - float:
8.0 - float:
2.0 - float:
-2.0 - float:
2.71692...$\approx e$
Control flow: variables¶
Variables are names which refer to values.
x = 10
2 * x + 4
#Prefer descriptive names over shorthand
import math
planck = 6.63e-36
red_planck = planck / (2 * math.pi)
red_planck
name = 'Dr. John Smith' #not just numbers: more data types later
len(name)
thing1 = 3.142 #numbers okay in variable names
thing2 = 1.618
3rdthing = 2.718 #except at the start
Some keywords are forbidden.
del = 'boy'
To compare variables and/or values, use two equals signs ==. More on this later.
t = 2
t + t = 4
t + t == 4
Quick quiz: what happens here?¶
x = 1
y = x
x = x * 5
What's $y$ equal to: $1$ or $5$?
y
When we say y = x, we mean
- Make
yrefer to whateverxrefers to
and not
- Make
yrefer tox
If in doubt: try experimenting!
Control flow: functions¶
- Packages and the standard library have many useful functions
- Still useful to write your own: reuse code, break program into smaller problems
def discriminant(a, b, c):
print("a =", a, "b =", b, "c =", c)
return b ** 2 - 4 * a * c
defkeyword (define)- function name (same rules as variables)
- argument list
- colon to mark indentation
- statements: indented with four spaces
returnexpression
discriminant(2, 3, 4) #Give arguments values by position...
discriminant(b=3, c=4, a=2) #...or explicitly by name
Python will complain if you don't give a function the right arguments.
discriminant()
discriminant(0, 0)
discriminant(a=1, a=2, a=3)
Arguments can be made optional by giving them default values.
def greet(greeting='Hello', name='stranger'):
print(greeting, 'to you,', name)
greet()
greet('David')
greet(name='David')
Can return more than one value at once:
def consecutive_squares(n):
return n**2, (n + 1)**2
consecutive_squares(5)
The function returns a tuple (more on these later).
Can unpack to get at the individual values
a, b = consecutive_squares(10)
a
b
Variable scope: context matters¶
a = 3
def double(a):
a = 2 * a
return a
double(6)
Function arguments and variables defined in a function are local to the function body.
If there's a name conflict, stuff outside is unaffected.
a
See the Python tutorial for more tips, tricks and examples---including functions that take a variable number of arguments.
Cheeky challenge¶
Write a function implements the quadratic formula.
- Arguments: three numbers $a$, $b$, and $c$
- Return both solutions to $ax^2 + bx + c = 0$
- Return the smaller one first
Reminder: the quadratic formula is $$x = \frac {-b \pm \sqrt{b^2 - 4ac}} {2a}$$
- Use
math.sqrtfor computing square roots. Don't forget toimport!
Let's do a few tests.
- $(x-4)(x+2) = x^2 + 2x - 8$ has roots $x=4, x=-2$.
- $2(x-10)^2 = 2x^2 -40x + 400$ has a repeated root $x=10$.
print( quadratic_roots(1, 2, -8) )
#assert statements will error if the condition is False.
assert quadratic_roots(1, 2, -8) == (-2, 4)
assert quadratic_roots(2, -40, 400) == (10, 10)
for i in range(5):
print("Hello!")
- loop body indented with four spaces (like functions)
- colon to denote indentation
Python's indexing convention¶
Something of length $N$ uses indices from $0$ to $N-1$ inclusive.
for i in range(5):
print("Here's a number:")
print(i)
for i in range(5, 10):
print(i)
for i in range(10, 20, 2):
print(i)
Python assumes that start ≤ stop.
for thing in range(50, 40): #can use any loop variable
print(thing)
If you want a descending loop you need a negative step.
for thing in range(50, 40, -3):
print(thing)
Cheeky challenge¶
Use a loop to compute $$5^2 + 10^2 + 15^2 + 20^2 + \dotsb + 200^2$$
#Again here's a template for you
total = 0
for ... in ...:
total = total + ...
total
#Here's the answer you should have got:
assert total == 553500
We'll see later that we can loop over all sorts of objects---not just ranges.
for character in "David Matthew Robertson":
print(character, end=".")
This makes looping a really powerful tool in Python. It enables
- Shortcuts like the
enumeratefunction - Generator expressions and generator functions
- List/Set/Dictionary comprehensions
- Efficient looping techniques
Just like other languages, there are while loops and break and continue statements which are a bit less intuitive.
There's too much to go over here---but there are links in the notebook if you're curious.
Control flow: conditionals¶
A very important tool in the programmer's toolkit is the ability to do different things in different circumstances.
Enter the if statement:
i = 10
if i % 2 == 0:
print(i, "is even")
- Colon, then four spaces before body statements
- Main expression usually a boolean:
TrueorFalse - Use comparisons like
<,<=,==,!=,>=,>to make booleans
1 < 2 #less than
2 <= 0.2 #less than or equal
3 == 3.0 #equal
"cat" != "dog" #not equal
x = 10
1 < x < 15 #Mathematical notation for "(1 < x) and (x < 15)"
Let's take our previous if statement and put it in a loop.
Whenever we start a new block (line ending in a colon), we have to indent an extra four spaces.
for i in range(5):
if i % 2 == 0:
print(i, "is even")
We can handle the False case with an else statement.
for i in range(5):
if i % 2 == 0:
print(i, "is even")
else:
print(i, "is odd")
For finer control, use an if... elif... else... chain.
Here elif is short for "else if".
import datetime
now = datetime.datetime.now()
print("The time is", now, "and the hour is:", now.hour)
if 6 <= now.hour < 12:
print("Good morning!")
elif now.hour < 18:
print("Good afternoon!")
elif now.hour < 20:
print("Good evening!")
else:
print("Good night!")
elseis optional and always comes last.- Need to have
ifbefore anyelifs. - Can have as many
elifs as you like.
Cheeky challenge¶
The sign or signum function is defined by $$\operatorname{sign}(x) = \begin{cases} \phantom{-}1 & \text{if $x>0$} \\ \phantom{-}0 & \text{if $x=0$} \\ -1 & \text{if $x<0$} \end{cases}$$
Implement this as a Python function.
#And some tests:
assert sign(10) == 1
assert sign(0) == 0
assert sign(-23.4) == -1
- Quick mention: can perform logical operations on booleans with
and,or, andnot.
True and False
True or False
not False
not False and False #careful with order of operations
not (False and False)
supercal = "Supercalifragilisticexpialidocious"
starwars = 'No, I am your father' # spaces okay
greeting = "こんにちは (Konnichiwa)" # non-Latin characters okay
- Use
\nto stand for a newline - Use
\'or\"for literal quotes - Use
\\for a literal backslash - Spaces preserved
print("A short 'quote'\n a double quote char: \"\n and newlines!")
Python is pedantic when comparing¶
'2' == 2 #different types!
type('2'), type(2)
'True' == True
type('True'), type(True)
String methods¶
A list of handy funtions for working with strings. Full reference online.
vowels = "aeiou"
vowels.upper()
vowels.lower() #already lowercase
vowels.capitalize()
len(supercal) #length function
supercal.count("a")
Silly example: a function which processes a yes/no prompt (y/n)
def handle_response(response):
if response.startswith("y"):
return "positive response"
elif response.startswith("n"):
return "negative response"
else:
return "unclear response"
handle_response("yes")
handle_response("no way man that's unreasonable")
What happens when we call with these arguments? Guess, then check in the notebook.
handle_response()handle_response("")handle_response("YES")handle_response(" yes ")
handle_response()
TypeError: missing argument
handle_response("")
- Unclear response: the empty string
""doesn't start with anything!
handle_response("YES")
- Unclear response: upper/lowercase matters for comparison
'Y' == 'y'
handle_response(" yes ")
- Unclear response: first char is a space
Often useful to normalise strings to a sensible form, especially if they come from user input.
response = " YeS "
response = response.lower()
print( repr(response) ) # explicitly representation with repr()
response = response.strip() # remove whitespace from start and end
print( repr(response) )
Also handy: str.replace:
x = "The news media reported today that no news is in fact good news"
x.replace("news", "FAKE NEWS!!")
Slicing¶
Remember that indexing works from $0$ to $N - 1$:
supercal[0]
supercal[5]
supercal[0:5] #like range, slicing excludes upper limit
supercal[-1] #Last char
supercal[:5] + "..." + supercal[-4:] #first five, then last 4
name = "David"
"Good morning, " + name + "."
- Use
*as shorthand for repitition.
'thank you ' * 10
Even more complicated string handling available:
Looping over strings¶
Awkward way:
example = "demo"
for i in range(len(example)):
print(example[i])
Slick way:
for character in "demo":
print(character)
Cheeky Challenge¶
Write a function to count the number of vowels in a string. Assume that we're just working with the Roman alphabet---so don't worry about variants like ë, è, é, and ê.
For bonus points, try using a loop to write this function.
#Here's a space to write your function
#and some tests to run
assert your_function("Hello") == 2
assert your_function(" xyz HEllO") == 2
assert your_function("Hello, sailor") == 5
Data types: lists and tuples¶
- Lists: a sequence of arbitrary Python objects
greek_letters = ["alpha", "beta", "gamma", "delta"]
greek_letters[1] #Index just like strings: 0 to N-1.
- Lists can be modified in-place
greek_letters[1] = "BETA (β)"
greek_letters
- Lists can contain objects of different types
things = ["uno", "dos", 3, supercal, 2.718]
- Unless they're modified, lists have a fixed length
len(things)
- Lists are objects, so lists can even contain lists!
names_by_parts = [ ["David", "Robertson"], ["Cetin", "Can", "Evirgen"] ]
print( names_by_parts[0] )
print( names_by_parts[0][1] )
len(names_by_parts)
- A list doesn't know anything special about what it contains
- Can't access or add new list items by accident
greek_letters[4]
greek_letters[4] = 'EPSILON (ε)'
- Use list methods to modify the list itself, rather than its contents.
- See also full list description
greek_letters.append("EPSILON (ε)")
greek_letters
- Other useful list methods and idoms:
empty_list = []
print(empty_list, len(empty_list))
numbers = [5, 2, 64, 41, 27, -2, 11, 32]
numbers.sort() #modifies list in place
numbers
["ab", 1].sort() # Can't compare text with numbers
x = list(range(10, 20))
x
del x[2] #Delete the entry with index 2 (third entry)
x
print("POP:", x.pop(), x)
x.reverse() #modifies in place
x
x.insert(4, "surprise")
x
NB: It's quick to extend lists at the end, but inserting or delete near the start is slower. If your list is HUGE then this can become a problem.
See also the Python wiki or these course notes.
Looping over lists is just like strings.
Warning: don't modify list structure when looping! (Modifying list values is fine)
colours = ["red", "orange", "yellow", "green", "blue", "indigo", "violet"]
for colour in colours:
print(colour, "has", len(colour), "letters" )
for colour in colours:
colours.pop()
colours
for i, colour in enumerate(colours): #avoids range(len(colours))
colours[i] = colour.upper()
colours
with open('data/en-GB-words.txt', 'rt') as f:
words = [line.strip() for line in f]
print(len(words), "words. Number 2001 is", words[2000])
N = len(words)
print(words[0], words[N//2], words[-1], sep=", ")
count = 0
for word in words:
if 'e' in word:
count = count + 1
print(count, 100 * count / len(words))
two_letter_words = []
for word in words:
if len(word) == 2:
two_letter_words.append(word)
print(two_letter_words)
Tuples¶
- The same as a list, except can't be modified after creation.
- Created with round brackets, not square
- Still indexed from $0$ to $N-1$
coordinate = (1, 2, 3)
coordinate
coordinate[0]
coordinate[0] = 10
x, y, z = coordinate #tuple unpacking
print(x, y, z, x + y + z)
In fact, when you say return a, b from a function, what gets returned is the tuple (a, b)!
Data types: dictionaries¶
- Unordered collection of pairs
key -> value - Keys usually strings
- "Hashmap", "Associative array"
david = dict(
surname = "Robertson",
given_names = ["David", "Matthew"],
age = 24,
dob = "26/06/1992",
height = 190
)
david
- Index by key to get/set values
david['age'] = "very very very very very very old"
david['age']
Three ways to loop:¶
for key in david:
print(key, end=", ")
for value in david.values():
print(value, end=", ")
for key, value in david.items():
print(key, "->", value)
- Dictionaries have a length too:
len(david)
- Python will complain if you ask for a missing key:
david['weight']
- Can check if a key is present with
in:
'surname' in david
- NB: The Python community tends to prefer
dict.get()or exception handling when keys might be missing.
Cheeky challenge¶
The following data file contains the periodic table as a dictionary. We're going to load it into a list, and each entry of that list will be a dictionary.
import os
import json
with open("data/PeriodicTable.json", "rt") as f:
table = json.loads(f.read())['elements']
table[0]
Your challenges:
- Which element is densest?
- Create a new dictionary mapping elements' symbols to their names. For example, if
Dis the dictionary,D['H'] == 'Hydrogen'. - Sorted alphabetically, what's the first and last element symbol?
- Sorted alphabetically, what's the first and last element name?
- How many elements' symbols have a different first letter to their name?
max_density = 0
max_density_name = ""
for element in table:
if element['density'] != None and element['density'] > max_density:
max_density = element['density']
max_density_name = element['name']
max_density, max_density_name
shorthand = {}
for element in table:
symbol = element['symbol']
name = element['name']
shorthand[symbol] = name
shorthand
symbols = list(shorthand)
symbols.sort()
symbols[0], symbols[-1]
names = list(shorthand.values())
names.sort()
names[0], names[-1]
oddballs = {}
for symbol, name in shorthand.items():
if name[0] != symbol[0]:
oddballs[symbol] = name
oddballs
After lunch:¶
- Can will give a crash course in Python's scientific libraries
- Some more exercises, chances to practise